You can build customized code with JAXB — the Java API for XML Binding. With JAXB, you take an XML document and you make a Java class file that's perfect for processing the document. When your needs change and the class no longer does what you want it to do, you just spawn a new subclass.
When you write SAX or DOM code, you create an XML processing program. Your program reads a document, and uses the document to do useful work — starting with something harmless like public void startElement or node.getNodeName(). Either way, your program makes no assumptions about what's inside the document. The document has a root element, some child elements, and that's all. Any special assumptions you make about this document actually narrow the usefulness of the code.
Versatile code versus customized code
Consider the code in Listings 1 and 2. Listing 1, scans five nodes in a document tree. Those five nodes have to be arranged a certain way, or else the program crashes. (The listing wants a comment and a root node, with at least two children directly under the root node.)
Listing 1: Displaying a few nodes
import org.w3c.dom.Node;
import org.w3c.dom.NamedNodeMap;
class MyTreeTraverser
{
MyTreeTraverser (Node node)
{
System.out.println(node.getNodeName());
node = node.getFirstChild();
System.out.println(node.getNodeName());
node = node.getNextSibling();
System.out.println(node.getNodeName());
node = node.getFirstChild();
System.out.println(node.getNodeName());
node = node.getNextSibling();
System.out.println(node.getNodeName());
}
}
Listing 2: Traversing the DOM tree
import org.w3c.dom.Node;
import org.w3c.dom.NamedNodeMap;
class MyTreeTraverser
{
Node node;
MyTreeTraverser (Node node)
{
this.node = node;
displayName();
displayValue();
if (node.getNodeType() == Node.ELEMENT_NODE)
displayAttributes();
System.out.println();
displayChildren();
}
void displayName()
{
System.out.print("Name: ");
System.out.println(node.getNodeName());
}
void displayValue()
{
String nodeValue = node.getNodeValue();
if (nodeValue != null)
nodeValue = nodeValue.trim();
System.out.print("Value: ");
System.out.println(nodeValue);
}
void displayAttributes()
{
NamedNodeMap attribs = node.getAttributes();
for (int i = 0; i < attribs.getLength(); i++)
{
System.out.println();
System.out.print("Attribute: ");
System.out.print(attribs.item(i).getNodeName());
System.out.print(" = ");
System.out.println(attribs.item(i).getNodeValue());
}
}
void displayChildren()
{
Node child = node.getFirstChild();
while (child != null)
{
new MyTreeTraverser (child);
child = child.getNextSibling();
}
}
}
The code in Listing 2 is much more general. This code checks the document structure as it runs. When the code finds a child node, it scans the child and looks for grandchildren. If there are no grandchildren, the code looks for brothers and sisters. The code can handle any document tree — whether it has one node or a thousand nodes.
Thus, Listing 2 is more versatile than Listing 1. However, this versatility comes with drawbacks — including the possibility of very high overhead. The code in Listing 2 has to parse the entire XML document — and then put a representation of the document's tree into the computer's memory. If the document is very large, then the representation is large: Memory gets bloated with all that temporary data, and the code in Listing 2 slows to a crawl.
The benefits of customization
Imagine you're trying to drive to Faneuil Hall in Boston, Massachusetts. It doesn't matter where you start from; the trip will always be confusing and difficult. Anyway, you have to plan your route. You can get lost in nearby Revere or Cambridge or in downtown Boston. Depending on your resources, you have two options:
- You can stop at a gas station and buy a map. If you do, then you may never get to Faneuil Hall. After all, you have to find where you are on the map, look for alternative routes, choose a route, and then (heaven help you) try to follow the route without getting lost again.
- You can tell your expensive, talking GPS system that you want to get to Faneuil Hall. The system will plot a customized route and guide you, turn by turn, from whatever miserable place you're in to the optimal route that leads from there to Faneuil Hall. The route is so customized that the GPS voice says (for example), "There's no sign at this intersection, but turn left anyway." Later on, the voice says "There are two signs at this intersection, and the signs contradict each other. But turn right anyway."
Using the paper map takes more work (more time, effort, dexterity, and patience) than using the talking GPS. Why? Because the paper map isn't customized to your specific needs; in effect, it says, "Here's the entire Boston metropolitan area. Faneuil Hall is in there somewhere. You figure out what to do next."
A custom system is (as you might expect) easier to use than one that isn't tailored to your immediate situation. Thus, the XML processing code of Listing 2 makes a huge, resource-gulping DOM tree in your computer's memory space ("Here's the tree — you figure out what to do next . . .") because the code isn't customized. The code works for any old document — not just the one you have on hand — and always gobbles up resources to do it.
The essence of JAXB
The idea behind JAXB is to create custom-tailored class to meet your present needs. You take the description of an XML document, run it through a special program called a schema compiler, and get a brand new class called the generated class. This generated class is streamlined to work with particular XML documents.
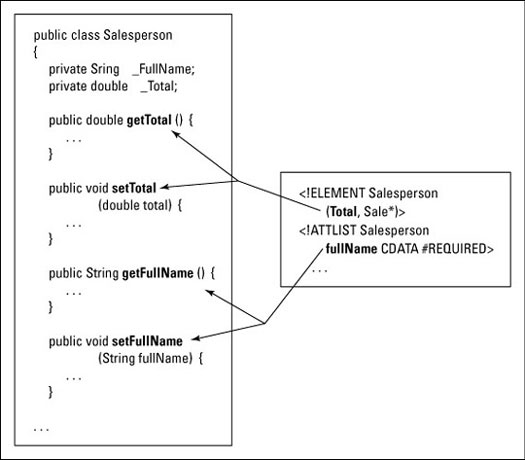
For example, if your XML documents have elements named Total, then the generated class can have setTotal and getTotal methods. If a document's element has a fullName attribute, then the generated class can have setFullName and getFullName methods. (See Figure 1.)
The connection between a part of an XML document and a part of a Java class is called a binding. With all these bindings, an instance of the class represents a single XML document.
>
>
Figure 1: An object represents a document.
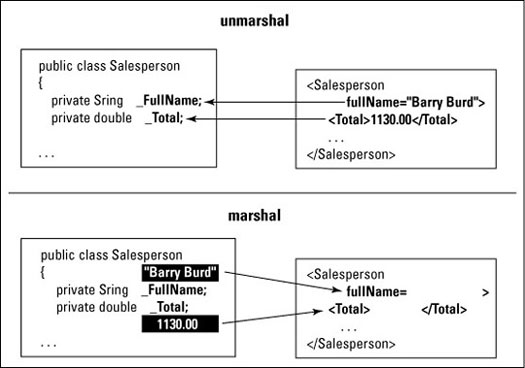
So how do you connect an object with an XML document? Well, the generated class has methods named unmarshal and marshal. (See Figure 2.)
- The unmarshal method reads an XML file. The method gets values from the XML document, and assigns these values to variables in the Java object.
- The marshal method writes an XML file. The method gets values from the Java object, and uses these values to create the XML document.
With methods like these, you can retrieve and modify the data in an XML document.
>
>
Figure 2: Reading and writing values.
>
dummies
Source:http://www.dummies.com/how-to/content/building-custom-code-with-java-api-for-xml-binding.html
No comments:
Post a Comment